A few months ago, a Science paper reported the results of an attempt to replicate 100 studies published in three top psychology journals between 2011-2014. The authors concluded:
“A large portion of replications produced weaker evidence for the original findings despite using materials provided by the original authors, review in advance for methodological fidelity, and high statistical power to detect the original effect sizes.”
This week, Science published a commentary co-authored by Daniel Gilbert, a prominent Harvard psychologist, drawing the opposite conclusion from the same data:
“Indeed, the data are consistent with the opposite conclusion, namely, that the reproducibility of psychological science is quite high.”
The authors of the psych replication paper have also published a response.
Together with these two letters, a research article co-authored by yours truly reports a multi-lab study attempting to replicate 18 experiments published in two leading economics journals, American Economic Review (AER) and the Quarterly Journal of Economics (QJE) between 2011-2014.
Below are the results of the two projects juxtaposed. There are many possible metrics for measuring the replicability of a study. Here, I counted a “successful replication” as either a statistically significant (p<0.05) replication effect (green) or a statistically significant meta-analytic effect when combining the original study and the replication (blue).
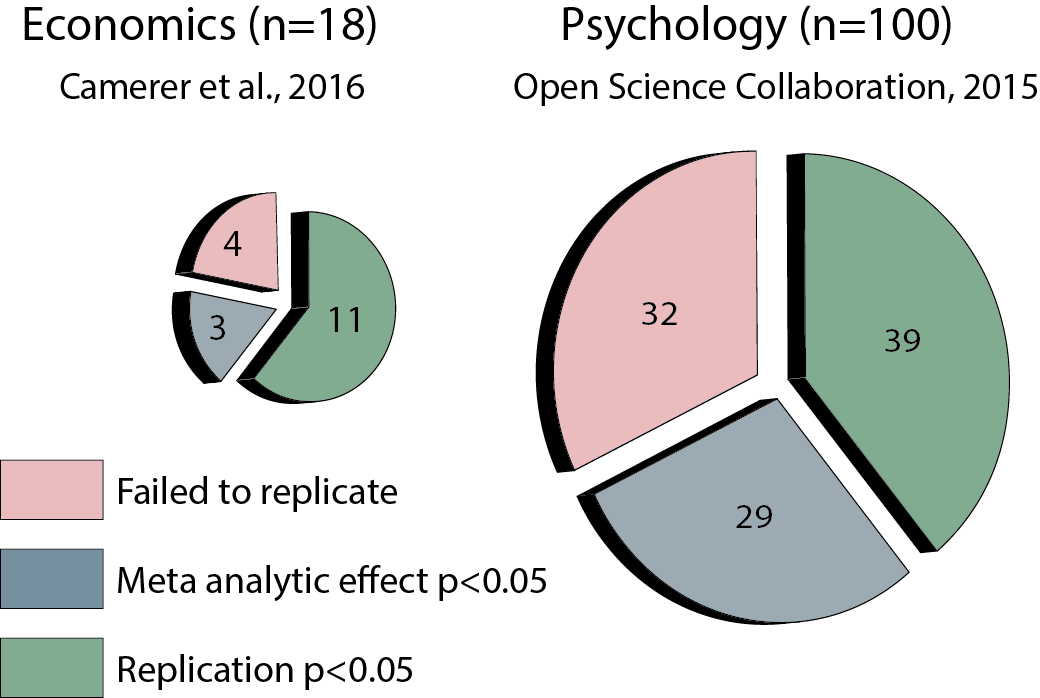
As can be clearly seen from the results above, replication rates in the econ project were much higher than those of the psych project, albeit the number of studies was grater in the psych project.
In this post, I will try to articulate what I see as the main point of Gilbert et al.’s commentary and explore what the econ project can teach us about the state of the psych literature.
Causes of failure to replicate
A replication attempt can fail because of two main reasons:
- The original effect is not real. In other words, the original study is a false positive, or a “type I error”.
- The original effect is real, but the replication could not detect it. In other words, the replication study was a false negative, or a “type II error”.
We should update our beliefs regarding the true state of the world (e.g., “there is/ isn’t a replication crisis”) differently in these two cases.
The chance of successfully replicating in case (A) depends only on the original study; it will be low when replicating a false positive, regardless of the power of the replication study. This however is not the case for (B), where success depends on the replication’s statistical power: the chance of successfully rejecting the null hypothesis given that the effect is real.
For a given effect size, increasing statistical power (and reducing the chance of case B’s) can be achieved by increasing the number of participants in the replication. As running more subjects costs money and takes time, researchers typically set the replication’s sample size to the minimum required for achieving sufficient statistical power (a standard power is between 80% and 90%). In practice, this is done using a mathematical formula, which is implemented by power calculators estimating the required sample size given the expected effect size.
But… what is the expected effect size in the replication?
It is difficult to determine exactly what effect size we should expect in the replication. If we knew, we wouldn’t have to run the study, right? As a proxy, researchers typically use the effect size of the original study. This is reasonable, as the replication attempts to be as close as possible to the original study.
Gilbert et al.’s critique
All replications might differ from the original studies in many ways, from geographical locations and weather conditions to the point in history when they were conducted. A fresh example from the econ replication project is a study from 2011, reporting that inducing happiness decreases temporal discounting. The original study induced happiness by having participants watch a video of a performance by Robin Williams, who since then had committed suicide. The video manipulation failed to induce happiness in the replication study and the results did not replicate.
Since different subject pools are used across a study and its replication, there is plenty of reason to suspect that the pools might differ in important ways. Sometimes the behavioral task is also not perfectly replicated. As such, even if an effect were real, the effect size in a replication may be different than that in the original study – and relying on the original effect size for calculating statistical power would yield biased power calculations. This could potentially lead to more type II errors in the replication (case B).
Gilbert et al. bring several specific examples (that are addressed in the reply letter) for substantial differences between the original studies and the replication attempts of the psych project, that they call “infidelities”. They claim that these “infidelities”, together with differences between the subject pools, cause a bias that often works in one direction: against the chance of finding an effect.
Following the critique, I ran a few power calculations. The average effect size of replication studies in the psych project was about a half of the original, and in the econ project it was two thirds of it. Whatever the source of this shrinkage of effects in the replications may be [1] this suggests that reliance on the effect size of the original study might lead to underestimating the necessary sample size in the replication. This could lead to a greater chance of “case B” replication failures.
I calculated the chance of failing to detect a true effect when miscalibrating the power calculation with an overly optimistic effect size estimation (table below). The outcome is statistical power of only 58% if the (true) replication effect size is only two thirds of the original study and 38% if it were a half of it. These numbers closely match the replication rates of the econ and psych projects, correspondingly [2].
| Original effect size | Required sample for .9 power | Power achieved for a 2/3 effect size | Power achieved for a 1/2 effect size |
| 0.3 | 470 | 0.58 | 0.38 |
| 0.5 | 172 | 0.58 | 0.38 |
| 0.7 | 88 | 0.58 | 0.38 |
| 0.9 | 56 | 0.58 | 0.38 |
Moving forward: is there a replication crisis?
If we ignore several problems in the literature that we already know of (such as p-hacking and low statistical power) and accept the proposition that changes in the protocol more often introduce noise (rather than reduce it), Gilbert et al.’s interpretation holds water and the number of “successfully replicated” studies might be under-estimated. Does this mean that the “reproducibility of psychological science is quite high”, as they claim?
Much of the discussion of replication results has focused on various different metrics of replication that are concerned with estimating the percentage of studies that “successfully” replicate according to various criteria. In the previous section, I have (hopefully) convinced you that if we can live with an average replication effect size that equals a half of the original study, replication rates of the psychology project were actually going as expected if all of their effects were real.
The psych project replicated studies published in three of the most prestigious and influential psych journals. Most of its authors are psychology PhDs, some are prominent professors with a long publication list in top journals. They have invested a lot of time and unprecedented amounts of money to make the replications as close as they could to the original studies. The project was completely transparent and all of the data was made publicly available. It seems obvious that its sincere goal was estimating the true state of the literature, rather than finding a “crisis”.
So, if we accept Gilbert et al.’s criticism, there are only two possible conclusions.
- The original studies were too difficult to replicate directly without too many “infidelities”. As replication is a crucial part of every scientific process, this is a major problem.
- Very little deviations from the original protocol have shrunk the (true) effects of studies published in three top psych journals by a half on average.
Now comes the key question: is this the type of robustness that social scientists can live with, or can we do much, much better?
If there’s no much room for improvement, then the reproducibility of psychological science is quite high. But keep in mind, that psychological experiments are conducted in many different labs across the world and in many different points of time in history. The (ambitious) goal of psychological science is to find robust phenomena that inform general theories that tell us something about human behavior in the noisy world outside the lab. In order to make scientific progress, researchers must rely on the previous findings of their peers. If we can live with either of the two above conclusions, doesn’t it mean that the entire endeavor of psychological science is a waste of time and resources?
This makes the econ replication project important.
Like in the psych project, replications were conducted in different sites, with different subject pools, different experimenters and in different points in history compared to the original studies. The a-priori power calculations that were used were the same as in the psych project. This means that the econ replications also relied on the original over-estimated effect sizes when calculating the required sample size. But the econ results were different. And they suggest that something else might be going on – that is beyond a statistical artifact caused by inevitable “infidelities” in the replication process.
There is a misconception that the word “crisis” in Chinese is composed of two characters, one representing danger and the other opportunity. I will adopt this misconception here. Contrasting the results of the psych and econ replication projects showes that we can do much better. The replication crisis does exist, and it gives us hope for a brighter future.
In the next few posts, I will illuminate the differences in research practices between economics and psychology, and discuss whether they might have contributed to the differences in replication rates.
Disclosure: the author is neither an economist nor a psychologist
[1] The reason could be “infidelities”, but also case (A) errors (original studies are false positives) and publication bias.
[2] Some of the original effects are likely false positives (case A), and therefore the power calculations are somewhat pessimistic.
#Hookahmagic
Мы всегда с Вами и стараемся нести только позитив и радость.
Ищите Нас в соцсетях,подписывайтесь и будьте в курсе последних топовых событий.
Строго 18+
Кальянный бренд Фараон давно завоевал сердца ценителей кальянной культуры вариативностью моделей кальянов,
приемлемым качеством и низкой ценовой политикой. Именно эти факторы играют главную роль в истории его успеха. Не упускайте очевидную выгоду и вы! Заказывайте кальян Pharaon (Фараон) 2014 Сlick в интернет-магазине HookahMagic и оформляйте доставку в любой регион РФ. Мы гарантируем быструю доставку и высокое качество предоставляемой продукции.
https://h-magic.su/tortuga
Удачных вам покупок!
Ищите Нас…
#Hookahmagic
В настоящее время стало очень популярным курить кальяны. Это ему объяснение. Во-первых, кальян помогает снимать стресс. Во-вторых, люди, которые отказались от обычных сигарет или находятся в процессе отказа, используют кальян в качестве замены вредной привычки.
Приобрести кальян, аксессуары, табак для кальяна дешево можно в специализированном магазине. Продавцы консультанты всегда помогут подобрать лучший вариант. Но не все специалисты смогут ответить на главные вопросы курильщика: «Какие виды кальяна бывают?», «Сколько можно курить по времени?», «Почему иногда болит голова от кальяна?» и так далее. Всё это будет описано ниже в статье.
Какие бывают кальяны
В определенных барах персонал обычно начинают свой разговор с фразы: «Какой табак для кальяна вы бы хотели выбрать?». Но никогда не спрашивают какой кальян человек хотел бы покурить. Многие курильщики считают, что самое важное в таком процессе только лишь табак. Сами же кальяны обычно различают только по цвету и остальным внешним признакам. Курение могут испортить и другие факторы.
https://h-magic.su/mamun
К таким можно отнести:
Бренд кальяна;
Материал изготовления;
Способ забивки;
Размер колбы.
Мы всегда с Вами и стараемся нести только позитив и радость.
Ищите Нас в соцсетях,подписывайтесь и будьте в курсе последних топовых событий.
Amy,Tortuga,Alfa Hookah…
Строго 18+