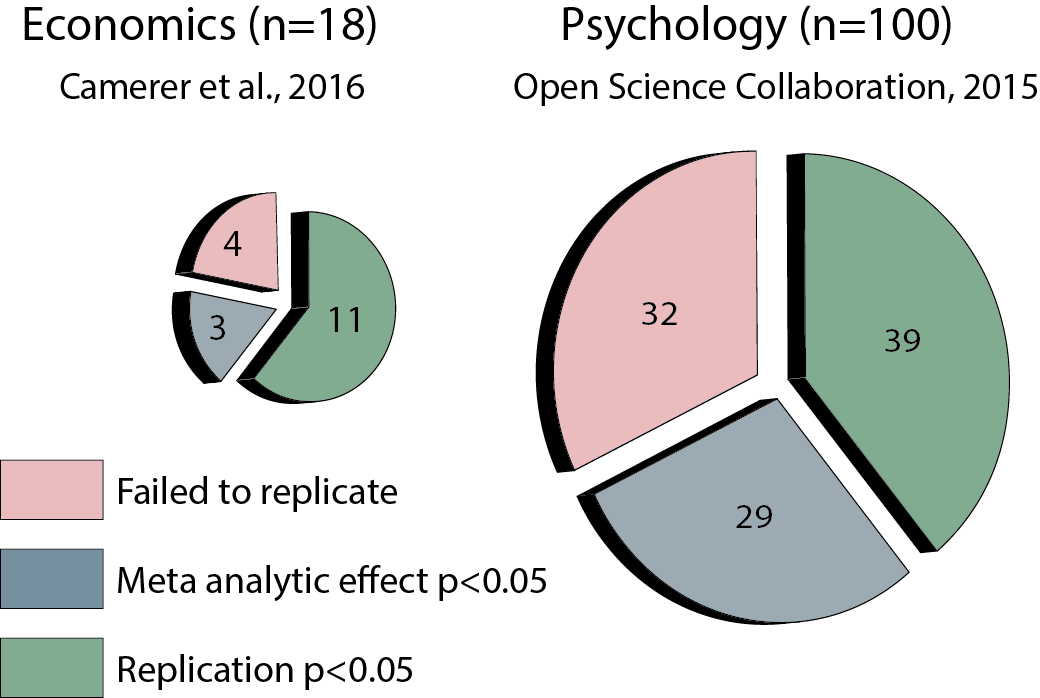
A study published today in Nature Human Behavior (co-authored by yours truly) reported the result of the Social Science Replication Project (SSRP) — a multi-lab effort that replicated 21 social science lab experiments published in Science and Nature in the years 2010-2015. All of the replications were pre-registered, and their statistical power was particularly high – with replication samples that were five times larger than the original studies (on average).
The SSRP attempted to replicate 21 studies, 13 of which replicated successfully. There is no guarantee that its general findings (such as replication rates) generalize to other literatures, but the results do have several interesting patterns – and they gave me 3 reasons to be cautiously optimistic about the current state of the experimental literature in the social sciences.
1. Researchers’ beliefs are well-calibrated
The SSRP results are nothing worth a celebration. The replication rate was 62% – which means that one’s chance of randomly picking a replicable social science finding from the world’s two most impactful journals is not much greater than betting on a coin flip. But keep in mind that the goal of science is not publishing replicable papers per se. Replicability is important because it is the means towards a greater goal: accumulating evidence about the “true state” of the world.
The SSRP allowed us to investigate whether the scientific community is indeed moving towards this goal. Before carrying out the replications, we conducted a survey asking 232 researchers (either PhDs or in a PhD program) about their beliefs regarding the chances that each study would successfully replicate.
Each circle in the figure below is one of the 21 studies that underwent replication in the SSRP, where the horizontal axis denotes the probability that the study would replicate according to the survey (averaged across the 232 researchers). Studies that successfully replicated are colored in blue, and studies that failed to replicate are in yellow. (The rectangles represent beliefs elicited using a prediction market, that highly correlated with the survey).
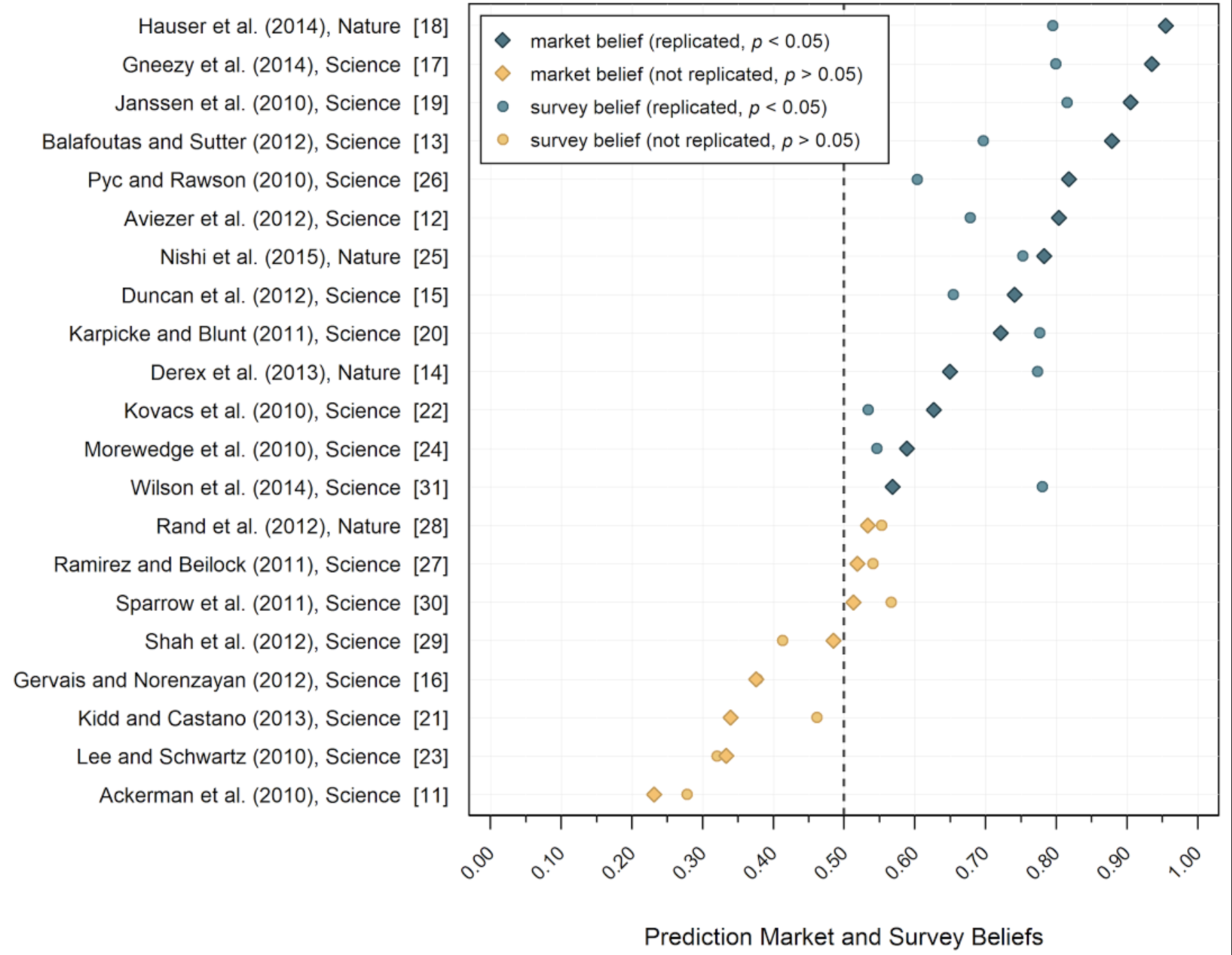
Notably, the dashed line at the 50% belief mark almost perfectly separates the blue studies from the yellow ones. No replicable (blue) studies scored less than 50% in the survey, and only three non-replicable studies exceeded 50%, but not by much. The correlation coefficient between the survey beliefs and the replication outcome was also quite high: r=0.842 (p < 0.001, n = 21)
We cannot be sure what the researchers had relied on when forming their beliefs about replicability. There are several likely possibilities — including features of the original studies (sample size, p-value), the theories that were tested, and evidence from later published (or unpublished) follow up studies. But regardless of what they were based on, the researchers’ capacities to predict replication outcomes suggest that much knowledge about the true state of the world had accumulated, at least among our survey participants.
2. The replicability rates of previous large-scale replication projects were likely under-estimated
A unique feature of the SSRP is the high statistical power of the replication studies. In the two previous large-scale replication projects, the Reproducibility Project Psychology (RPP) and Experimental Economics Replication Project (EERP), replications had about 90% power to detect the original effect size. In the SSRP, we used sample sizes that had 90% power to detect 75% of the original effect, and if a study failed to replicate (at the p<0.05 level), we collected additional data until we obtained 90% power to detect a half of the original effect.
The highly powered design of the SSRP implies that type II errors were far less likely in the SSRP. Indeed, the mean replication effect size of studies that failed to replicate in the SSRP was close to zero (0.3% of the original), and none of the 95% confidence intervals included even a half of the original effects. On the contrary, the 13 successful replications had strong evidence against the null: ten were statistically significant at the p<0.01 level, and eight at the p<0.001 level.
This allows us to disentangle original studies that are true positive from ones that are false positives — and estimate what effect size is expected when the original effect is true. Based on the 13 SSRP studies that replicated well, this effect size is 75% of the original, which reflects a systematic 33% inflation in the original reports. This inflation could be explained by various means, including the well-known “file drawer” problem caused by publication bias. But regardless of its cause, this finding has significant implication on how the statistical power calculations of replication studies should be conducted.
The norm to date – that was adopted by the RPP and the EERP – has been to ensure that a replication study has a sample size which is large enough to achieve 90% power to detect the original effect. But if the original effect is inflated by ~33%, powering to detect it with a 90% power would only obtain 68% power in the replication. So, if the effect size inflation in the SSRP is generalizable to the literatures of the previous replication projects, it would imply that 32 out of the 100 replication studies of the RPP and ~6 out of the 18 replication studies of the EERP were a-priori expected to have type II errors. In other words, a half of the 64 papers that “failed to replicate” in the RPP, and six out of the seven papers that “failed to replicate” in the EERP are expected to represent true (but smaller) effects, that could not be detected in the replication due to low statistical power. This suggests that the replicability of the literatures that were evaluated by these projects may not as bad as previously thought.
3. More recent publications were more likely to replicate
The SSRP replicated studies published between 2010 and 2015, years during which attention to methodological details slowly increased in the social sciences – thanks to the publication of several highly influential papers (for example, the article “false positive psychology” appeared in November 2011, and since then it has been cited over 2,000 times). There were also changes in editorial policies, such as the introduction of open practice badges in Psychological Science.
This is evident in the replicability rates of the social science literature published in Nature and Science:
Nine papers were published between 2010-2011, Four of them successfully replicated.
Eight papers were published between 2012-2013, Four of them successfully replicated.
Four papers were published between 2014-2015. All of them successfully replicated.
Of course, this evidence is anecdotal (as it relies on a small sample of studies), it is not necessarily generalizable, and it is silent about causality (many other trends occurred between 2011-2015). But I’d take it as another reason for cautious optimism.